Using GitLab CI/CD for Automated Let's Encrypt Certificate Deployment
I previously wrote about setting up this blog on GitLab Pages1. Back then I set up HTTPS manually. This post is about how I’ve automated that process using GitLab CI/CD and Justin Aiken’s jekyll-gitlab-letsencrypt plugin for Jekyll.
Last time I used certbot-auto (it was called letsencrypt-auto at the time) to manually obtain and verify my Lets’s Encrypt certificate. If you have shell access to your webserver you can use certbot to automatically update your certificate. But I don’t have shell access; GitLab Pages are for static sites. However, all the steps involved in obtaining, installing, and verifying a Let’s Encrypt certificate can be automated as long as you have access to some kind of shell environment, and can publish the static results of the process.
That’s where GitLab CI/CD comes in.
It’s possible to write your own shell script and add it to your .gitlab-ci.yml file, but thankfully other people have already done that work. In this case, in the form of jekyll-gitlab-letsencrypt.
Configuring it involved adding it to my Gemfile:
group :jekyll_plugins do
gem 'jekyll-gitlab-letsencrypt'
end
And then updating my _config.yml:
gitlab-letsencrypt:
# Gitlab settings:
gitlab_repo: 'mlapierre/mlapierre.gitlab.io' # Namespaced repository identifier
# Domain settings:
email: 'mlapierre@gmail.com' # Let's Encrypt email address
domain: 'marklapierre.net' # Domain that the cert will be issued for
# Jekyll settings:
base_path: '/' # Where you want the file to go
pretty_url: true # Add a "/" on the end of the URL
filename: '_pages/letsencrypt_challenge.html'
# Delay settings:
initial_delay: 180 # How long to wait for Gitlab CI to push your changes before it starts checking
And then adding a job to my .gitlab-ci.yml:
renew-letsencrypt:
stage: build
script:
- bundle install
- bundle exec jekyll letsencrypt
only:
- schedules
Items in only specify how the renew-letsencrypt job can be executed. The schedules option allows the job to be run in a schedule.
And here is a scheduled pipeline that runs once a week:
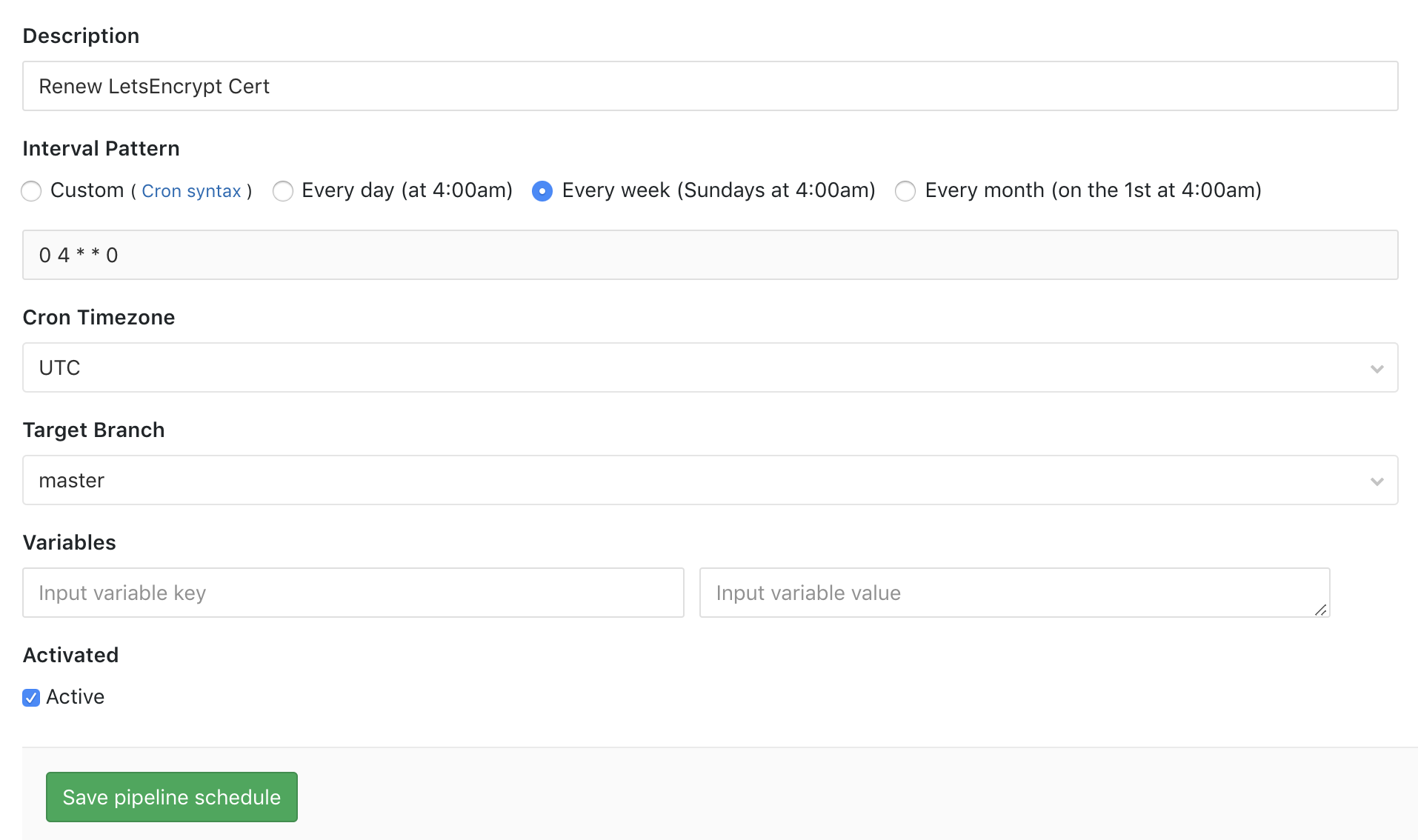
Let’s Encrypt certificates expire after 90 days but you can make the request to renew them as frequently as you like (within limits that most people wouldn’t reach).
For the plugin to work it needs push access to my blog’s repository on GitLab, and for that it needs a personal access token. If you want to use jekyll-gitlab-letsencrypt locally and will never publish your _config.yml you can provide your personal access token via:
gitlab-letsencrypt:
personal_access_token: 'ENTER SECRET HERE'
But if you use GitLab CI/CD you can provide it more securely via an environment variable, GITLAB_TOKEN. You can do that via Settings -> CI/CD -> Variables:
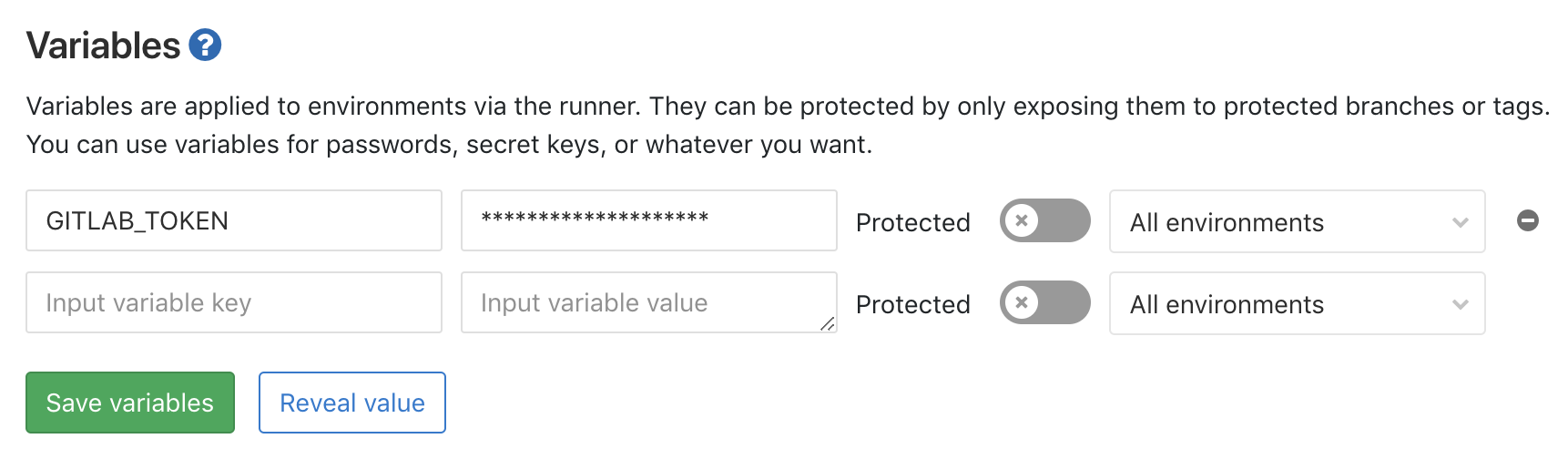
When the scheduled job executes, the plugin takes care of publishing the challenge file that the Let’s Encrypt service verifies, and then it uses the GitLab API to update my certificate in my GitLab Pages settings:
$ bundle exec jekyll letsencrypt
Configuration file: /builds/mlapierre/mlapierre.gitlab.io/_config.yml
Registering mlapierre@gmail.com to https://acme-v01.api.letsencrypt.org/...
Pushing file to Gitlab
Commiting challenge file as _pages/letsencrypt_challenge.html
Done Commiting! Check https://gitlab.com/mlapierre/mlapierre.gitlab.io/commits/master
Going to check http://marklapierre.net/.well-known/acme-challenge/d7D2-lvQqQJSolI42L9RSaOjQYBQrBSQsFWdzYELLJM/ for the challenge to be present...
Waiting 180 seconds before we start checking for challenge..
Got response code 200, file is present!
Requesting verification...
Challenge status = pending
Challenge is valid!
Updating domain marklapierre.net pages setting with new certificates..
Success!
All finished! Don't forget to `git pull` in order to bring your local repo up to date with changes this plugin made.
Job succeeded
And now I don’t have to bother manually updating my certificate. Many thanks to Justin and everyone else who did all the hard work!
1. In the interest of transparency, I should note that since writing that post I've started working for GitLab. More on that in another post.